Clojure is the future of AI coding, but you won't use it
I enjoy using Claude Code, but I always run it only on a VPS under root user with the "dangerously skip permissions" parameter — so that I don't have to confirm what it's doing, but I also don't want it to accidentally delete my personal files or leak private keys or API tokens I didn't explicitly copy to the VPS.
I don't believe in carefully configuring rights, or trusting AI to be smart enough to not accidentally do something that cannot be undone. I am not smart enough to reliably do this correctly even for my own actions — surely I can't contain a computational superintelligence powered by a malicious prompt injection by hackers or a benevolent prompt improvement by LLM vendors.
My today's shower thought was: "what thing in principle lets me be sure that I will get any useful work done in such a fragile environment when I can't trust my agent to always do the right thing and not destroy my work?". The answer came quickly: it's the Git version control system. I commit any pieces of work done, and push them to remote storage. If Claude Code destroys my VPS or infests it with crypto miners, I just make a new VPS and clone my repo there, and continue as if nothing happened. If my agent makes any bad changes to my code or even tampers with the repository files, I can always undo any changes I don't like. This is the only reason I am not paralyzed by fear and doubt accumulated from two decades of programming, and can sleep calmly.
Git, but for running software systems?
Then I though, wait... Aren't there often reports that AI agents ruined someone's production application, deleted/mangled some important data — and comments under those are: 1) one should not allow agents to operate in prod, 2) one should fine-tune permissions for agents, 3) one should supervise agents with other agents, and, of course, 4) the importance of periodic backups.
But, standing in shower, this appeared ridiculous to me. Programmers don't (anymore) do "backups copies of source code folders", they use Git because it's so much better in so many ways. AI agents are here to stay (and to grow bigger and more important every month) — it is obvious to me that your production database must just be Git-like, you should be able not only to simply undo any destructive action in the database, you must be able to time-travel over all past states of the database to "check out" its past versions "in another branch" to query its interconnected entities the same way you can in your current database.
That's literally the description of Datomic database though (written in Clojure btw). I asked my preferred LLM for any other examples of application DBs that possess such features — and only two popped up (XTDB and Datahike, both heavily inspired by Datomic, both written in Clojure btw). Nothing else, correct me if I am wrong.
When, in the future, apps — developed, deployed, and managed by AI agents — use Datomic-like, Git-like databases, we will be able to sleep calmly. Anything bad happens — we just ask agents to roll back the change, or cherry-pick correct values from immutable history of previous valid state snapshots. Nothing important ever gets lost or broken beyond repair.
Thoughts on why Clojure is the future for AI-programming
Why Datomic is unique like that? It think because its ideas are the underlying philosophy of Clojure, expressed as a general-purpose production-ready database. Probably people don't get exposed to Clojure's ideas a lot, and when they do, they either just start using Datomic or another Datomic clone (or at least lament that they are not allowed to).
Here's what else, I think, makes Clojure very useful for coding by AI agents.
I have three very intertwined conflicting thoughts.
- I don't want to write all the code anymore, because I am lazy, and not that young, and also I hate doing things that I know don't need to be done.
- On the other hand, I don't want to treat source code as a black box, because I want to control what I feel is important in the result.
- I don't think just mechanistically growing LLMs' context size or "smartness" will solve programming complex systems, so we can't just "wait three months".
Let's start with the third thought. The bigger a program becomes, the more difficult for an LLM agent it is to continue working with it productively. As I understand, it stems from the fact that as program's size grows, the "context" of an AI grows (amount of source code the AI must consider). The way LLMs work is that everything potentially interacts with everything in the context, so computation grows as n² from source code size (with many tricks to reduce the steepness of the function). But code doesn't simply interact with another part of the source code in a flat way, it also runs, so code interacts with its dynamic call stack (with whatever combinations of nested function calls possible at runtime), it also interacts with all possible combinations of runtime states, and also all possible combinations of external events coming from people and other programs.
So effectively, the computation amount to program correctly should grow not as n² from program size, but with much higher power. What's the solution? We meatbags historically have had similar constraints, so we invented factoring code (trapping complexity demon in crystal) — it works for us, it works for AI just as well. We split programs into smaller weakly interacting pieces that can be complex inside, but simple on the outside — and the mastery in this art is what makes a strong and experienced programmer.
Ideally, what I would like in AI coding, is that I, as a human, control only the small clean, slowly changing surface of inter-module interactions and the data types the modules are allowed to communicate with, but how they are implemented inside — I don't know, I don't want to know, as long as the only way the modules can affect each other — is with data structures of the types that I explicitly reviewed and allowed. Actually, I like that even for coding in human teams.
This way, I can be sure that the business logic is correct, and that all modules are exhaustively tested to be correct on the edges, but the actual implementation remains a completely fluid mess of code that my mind is too meaty to understand.
For example, some component of your system streams today's temperature to another.

We want the entities sent to be "temperature snapshots" that:
- have today's lowest temperature, highest temperature, and current temperature
- temperature is a positive (in Kelvin, we don't want the Celsius/Fahrenheit debate) double-precision floating point (finite: not infinity, not NaN)
- low <= current <= high
— a very reasonable data type with constraints I want to control. Here's how I describe it in Clojure.

Here's a one-liner to generate 100k valid random temperature snapshots for tests.
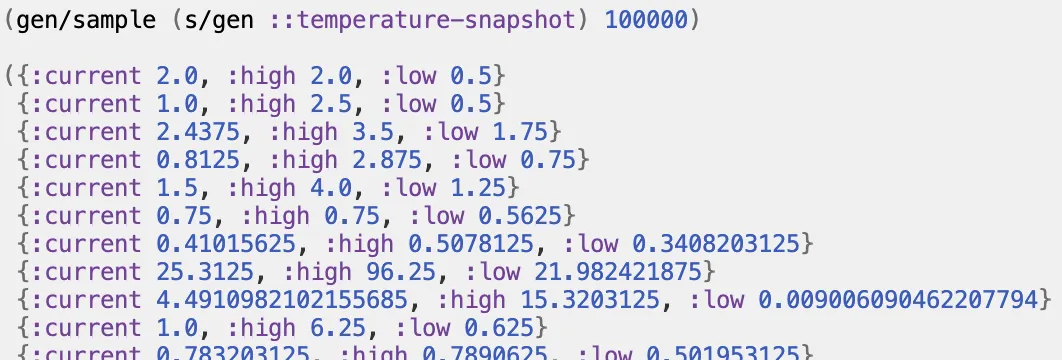
How would you describe this data type and generate exhaustive unit-test data in your favorite programming language? I believe we need this level of type definition with arbitrary constraints on what AI's code generates and crosses modules' boundaries, and this level of testing — millions of randomly generated unit tests for critical areas.
One could say: "But Timur, Clojure also has
- efficient immutable data structures that are effectively a Git for program's data in memory allowing arbitrary navigation, snapshots, and history,
- an observable asynchronous data flow framework with plug-and-play uniform interconnected modules,
- explicit stateful references that dramatically simplify state management and concurrency, thus reducing the cognitive complexity power even further,
- fully-reloadable runtime workflow that not only lets one change function's code while the program is running, but also allows an AI (or human) to write new program features piece by piece while the program is running without losing runtime state due to recompilation/restarts"
— to that I would reply: yes, you're right, all this also helps with AI coding, in my opinion.
Why you won't use Clojure
The problem with Clojure is that it though simple, not that easy. It's hard! It has a rather high skill floor and a steep learning curve, so that mostly only experienced programmers can deeply appreciate the decisions that made it possible. I am almost a decade into it, and I still keep finding new things to appreciate.
Therefore Clojure cannot be popular, therefore it cannot have many jobs, therefore it will not be popular.
However, I think that other languages, frameworks, and ecosystems will inevitably borrow quite a few ideas that Clojure got right — as they have been doing before, but this time allowing us to manage the AI coding mess.